

At FMS 2024, the technological requirements from the storage and memory subsystem took center stage. Both SSD and controller vendors had various demonstrations touting their suitability for different stages of the AI data pipeline - ingestion, preparation, training, checkpointing, and inference. Vendors like Solidigm have different types of SSDs optimized for different stages of the pipeline. At the same time, controller vendors have taken advantage of one of the features introduced recently in the NVM Express standard - Flexible Data Placement (FDP).
FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.
Silicon Motion's MonTitan Gen 5 Enterprise SSD Platform was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.
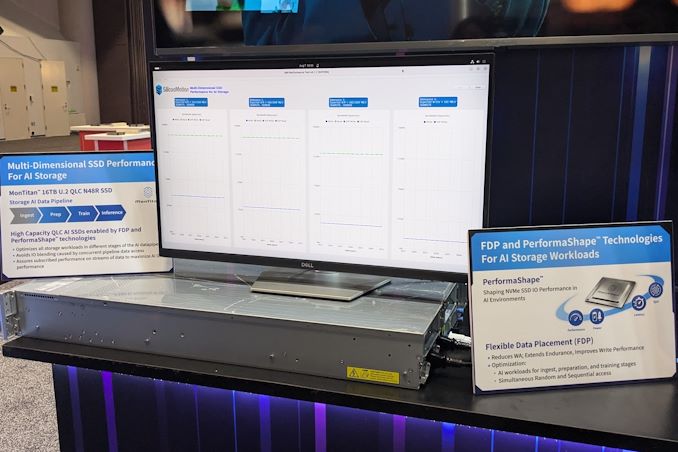
At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.
Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.
Storage

The CXL consortium has had a regular presence at FMS (which rechristened itself from 'Flash Memory Summit' to the 'Future of Memory and Storage' this year). Back at FMS 2022, the company had announced v3.0 of the CXL specifications. This was followed by CXL 3.1's introduction at Supercomputing 2023. Having started off as a host to device interconnect standard, it had slowly subsumed other competing standards such as OpenCAPI and Gen-Z. As a result, the specifications started to encompass a wide variety of use-cases by building a protocol on top of the the ubiquitous PCIe expansion bus. The CXL consortium comprises of heavyweights such as AMD and Intel, as well as a large number of startup companies attempting to play in different segments on the device side. At FMS 2024, CXL had a prime position in the booth demos of many vendors.
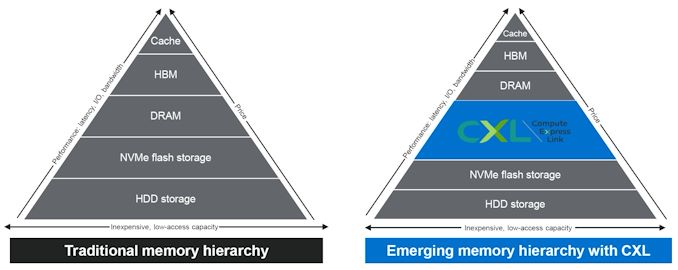
The migration of server platforms from DDR4 to DDR5, along with the rise of workloads demanding large RAM capacity (but not particularly sensitive to either memory bandwidth or latency), has opened up memory expansion modules as one of the first set of widely available CXL devices. Over the last couple of years, we have had product announcements from Samsung and Micron in this area.
At FMS 2024, SK hynix was showing off their DDR5-based CMM-DDR5 CXL memory module with a 128 GB capacity. The company was also detailing their associated Heterogeneous Memory Software Development Kit (HMSDK) - a set of libraries and tools at both the kernel and user levels aimed at increasing the ease of use of CXL memory. This is achieved in part by considering the memory pyramid / hierarchy and relocating the data between the server's main memory (DRAM) and the CXL device based on usage frequency.

The CMM-DDR5 CXL memory module comes in the SDFF form-factor (E3.S 2T) with a PCIe 3.0 x8 host interface. The internal memory is based on 1α technology DRAM, and the device promises DDR5-class bandwidth and latency within a single NUMA hop. As these memory modules are meant to be used in datacenters and enterprises, the firmware includes features for RAS (reliability, availability, and serviceability) along with secure boot and other management features.
SK hynix was also demonstrating Niagara 2.0 - a hardware solution (currently based on FPGAs) to enable memory pooling and sharing - i.e, connecting multiple CXL memories to allow different hosts (CPUs and GPUs) to optimally share their capacity. The previous version only allowed capacity sharing, but the latest version enables sharing of data also. SK hynix had presented these solutions at the CXL DevCon 2024 earlier this year, but some progress seems to have been made in finalizing the specifications of the CMM-DDR5 at FMS 2024.
Micron had unveiled the CZ120 CXL Memory Expansion Module last year based on the Microchip SMC 2000 series CXL memory controller. At FMS 2024, Micron and Microchip had a demonstration of the module on a Granite Rapids server.

Additional insights into the SMC 2000 controller were also provided.
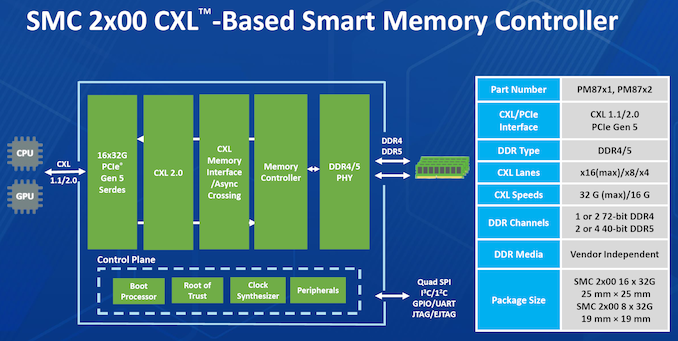
The CXL memory controller also incorporates DRAM die failure handling, and Microchip also provides diagnostics and debug tools to analyze failed modules. The memory controller also supports ECC, which forms part of the enterprise... Storage

It is with great sadness that I find myself penning the hardest news post I’ve ever needed to write here at AnandTech. After over 27 years of covering the wide – and wild – world of computing hardware, today is AnandTech’s final day of publication.
For better or worse, we’ve reached the end of a long journey – one that started with a review of an AMD processor, and has ended with the review of an AMD processor. It’s fittingly poetic, but it is also a testament to the fact that we’ve spent the last 27 years doing what we love, covering the chips that are the lifeblood of the computing industry.
A lot of things have changed in the last quarter-century – in 1997 NVIDIA had yet to even coin the term “GPU” – and we’ve been fortunate to watch the world of hardware continue to evolve over the time period. We’ve gone from boxy desktop computers and laptops that today we’d charitably classify as portable desktops, to pocket computers where even the cheapest budget device puts the fastest PC of 1997 to shame.
The years have also brought some monumental changes to the world of publishing. AnandTech was hardly the first hardware enthusiast website, nor will we be the last. But we were fortunate to thrive in the past couple of decades, when so many of our peers did not, thanks to a combination of hard work, strategic investments in people and products, even more hard work, and the support of our many friends, colleagues, and readers.
Still, few things last forever, and the market for written tech journalism is not what it once was – nor will it ever be again. So, the time has come for AnandTech to wrap up its work, and let the next generation of tech journalists take their place within the zeitgeist.
It has been my immense privilege to write for AnandTech for the past 19 years – and to manage it as its editor-in-chief for the past decade. And while I carry more than a bit of remorse in being AnandTech’s final boss, I can at least take pride in everything we’ve accomplished over the years, whether it’s lauding some legendary products, writing technology primers that still remain relevant today, or watching new stars rise in expected places. There is still more that I had wanted AnandTech to do, but after 21,500 articles, this was a good start.
And while the AnandTech staff is riding off into the sunset, I am happy to report that the site itself won’t be going anywhere for a while. Our publisher, Future PLC, will be keeping the AnandTech website and its many articles live indefinitely. So that all of the content we’ve created over the years remains accessible and citable. Even without new articles to add to the collection, I expect that many of the things we’ve written over the past couple of decades will remain relevant for years to come – and remain accessible just as long.
The AnandTech Forums will also continue to be operated by Future’s community team and our dedicated troop of moderators. With forum threads going back to 1999 (and some active members just as long), the forums have a history almost as long and as storied as AnandTech itself (wounded monitor children, anyone?). So even when AnandTech is no longer publishing articles, we’ll still have a place for everyone to talk about the latest in technology – and have those discussions last longer than 48 hours.
Finally, for everyone who still needs their technical writing fix, our formidable opposition of the last 27 years and fellow Future brand, Tom’s Hardware, is continuing to cover the world of technology. There are a couple of familiar AnandTech faces already over there providing their accumulated expertise, and the site will continue doing its best to provide a written take on technology news.
As I look back on everything AnandTech has accomplished over the past 27 years, there are more than a few people, groups, and companies that I would like to thank on behalf of both myself and AnandTech as a whole.
First and foremost, I cannot thank enough all the editors who have worked for AnandTech over the years. T... Site Updates


Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.

Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.

The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
The CXL consortium has had a regular presence at FMS (which rechristened itself from 'Flash Memory Summit' to the 'Future of Memory and Storage' this year). Back at FMS 2022, the company had announced v3.0 of the CXL specifications. This was followed by CXL 3.1's introduction at Supercomputing 2023. Having started off as a host to device interconnect standard, it had slowly subsumed other competing standards such as OpenCAPI and Gen-Z. As a result, the specifications started to encompass a wide variety of use-cases by building a protocol on top of the the ubiquitous PCIe expansion bus. The CXL consortium comprises of heavyweights such as AMD and Intel, as well as a large number of startup companies attempting to play in different segments on the device side. At FMS 2024, CXL had a prime position in the booth demos of many vendors.
The migration of server platforms from DDR4 to DDR5, along with the rise of workloads demanding large RAM capacity (but not particularly sensitive to either memory bandwidth or latency), has opened up memory expansion modules as one of the first set of widely available CXL devices. Over the last couple of years, we have had product announcements from Samsung and Micron in this area.
At FMS 2024, SK hynix was showing off their DDR5-based CMM-DDR5 CXL memory module with a 128 GB capacity. The company was also detailing their associated Heterogeneous Memory Software Development Kit (HMSDK) - a set of libraries and tools at both the kernel and user levels aimed at increasing the ease of use of CXL memory. This is achieved in part by considering the memory pyramid / hierarchy and relocating the data between the server's main memory (DRAM) and the CXL device based on usage frequency.
The CMM-DDR5 CXL memory module comes in the SDFF form-factor (E3.S 2T) with a PCIe 3.0 x8 host interface. The internal memory is based on 1α technology DRAM, and the device promises DDR5-class bandwidth and latency within a single NUMA hop. As these memory modules are meant to be used in datacenters and enterprises, the firmware includes features for RAS (reliability, availability, and serviceability) along with secure boot and other management features.
SK hynix was also demonstrating Niagara 2.0 - a hardware solution (currently based on FPGAs) to enable memory pooling and sharing - i.e, connecting multiple CXL memories to allow different hosts (CPUs and GPUs) to optimally share their capacity. The previous version only allowed capacity sharing, but the latest version enables sharing of data also. SK hynix had presented these solutions at the CXL DevCon 2024 earlier this year, but some progress seems to have been made in finalizing the specifications of the CMM-DDR5 at FMS 2024.
Micron had unveiled the CZ120 CXL Memory Expansion Module last year based on the Microchip SMC 2000 series CXL memory controller. At FMS 2024, Micron and Microchip had a demonstration of the module on a Granite Rapids server.
Additional insights into the SMC 2000 controller were also provided.
The CXL memory controller also incorporates DRAM die failure handling, and Microchip also provides diagnostics and debug tools to analyze failed modules. The memory controller also supports ECC, which forms part of the enterprise... Storage
It is with great sadness that I find myself penning the hardest news post I’ve ever needed to write here at AnandTech. After over 27 years of covering the wide – and wild – world of computing hardware, today is AnandTech’s final day of publication.
For better or worse, we’ve reached the end of a long journey – one that started with a review of an AMD processor, and has ended with the review of an AMD processor. It’s fittingly poetic, but it is also a testament to the fact that we’ve spent the last 27 years doing what we love, covering the chips that are the lifeblood of the computing industry.
A lot of things have changed in the last quarter-century – in 1997 NVIDIA had yet to even coin the term “GPU” – and we’ve been fortunate to watch the world of hardware continue to evolve over the time period. We’ve gone from boxy desktop computers and laptops that today we’d charitably classify as portable desktops, to pocket computers where even the cheapest budget device puts the fastest PC of 1997 to shame.
The years have also brought some monumental changes to the world of publishing. AnandTech was hardly the first hardware enthusiast website, nor will we be the last. But we were fortunate to thrive in the past couple of decades, when so many of our peers did not, thanks to a combination of hard work, strategic investments in people and products, even more hard work, and the support of our many friends, colleagues, and readers.
Still, few things last forever, and the market for written tech journalism is not what it once was – nor will it ever be again. So, the time has come for AnandTech to wrap up its work, and let the next generation of tech journalists take their place within the zeitgeist.
It has been my immense privilege to write for AnandTech for the past 19 years – and to manage it as its editor-in-chief for the past decade. And while I carry more than a bit of remorse in being AnandTech’s final boss, I can at least take pride in everything we’ve accomplished over the years, whether it’s lauding some legendary products, writing technology primers that still remain relevant today, or watching new stars rise in expected places. There is still more that I had wanted AnandTech to do, but after 21,500 articles, this was a good start.
And while the AnandTech staff is riding off into the sunset, I am happy to report that the site itself won’t be going anywhere for a while. Our publisher, Future PLC, will be keeping the AnandTech website and its many articles live indefinitely. So that all of the content we’ve created over the years remains accessible and citable. Even without new articles to add to the collection, I expect that many of the things we’ve written over the past couple of decades will remain relevant for years to come – and remain accessible just as long.
The AnandTech Forums will also continue to be operated by Future’s community team and our dedicated troop of moderators. With forum threads going back to 1999 (and some active members just as long), the forums have a history almost as long and as storied as AnandTech itself (wounded monitor children, anyone?). So even when AnandTech is no longer publishing articles, we’ll still have a place for everyone to talk about the latest in technology – and have those discussions last longer than 48 hours.
Finally, for everyone who still needs their technical writing fix, our formidable opposition of the last 27 years and fellow Future brand, Tom’s Hardware, is continuing to cover the world of technology. There are a couple of familiar AnandTech faces already over there providing their accumulated expertise, and the site will continue doing its best to provide a written take on technology news.
As I look back on everything AnandTech has accomplished over the past 27 years, there are more than a few people, groups, and companies that I would like to thank on behalf of both myself and AnandTech as a whole.
First and foremost, I cannot thank enough all the editors who have worked for AnandTech over the years. T... Site Updates
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage

Western Digital's BiCS8 218-layer 3D NAND is being put to good use in a wide range of client and enterprise platforms, including WD's upcoming Gen 5 client SSDs and 128 TB-class datacenter SSD. On the external storage front, the company demonstrated four different products: for card-based media, 4 TB microSDUC and 8 TB SDUC cards with UHS-I speeds, and on the portable SSD front we had two 16 TB drives. One will be a SanDisk Desk Drive with external power, and the other in the SanDisk Extreme Pro housing with a lanyard opening in the case.

All of these are using BiCS8 QLC NAND, though I did hear booth talk (as I was taking leave) that they were not supposed to divulge the use of QLC in these products. The 4 TB microSDUC and 8 TB SDUC cards are rated for UHS-I speeds. They are being marketed under the SanDisk Ultra branding.

The SanDisk Desk Drive is an external SSD with a 18W power adapter, and it has been in the market for a few months now. Initially launched in capacities up to 8 TB, Western Digital had promised a 16 TB version before the end of the year. It appears that the product is coming to retail quite soon. One aspect to note is that this drive has been using TLC for the SKUs that are currently in the market, so it appears unlikely that the 16 TB version would be QLC. The units (at least up to the 8 TB capacity point) come with two SN850XE drives. Given the recent introduction of the 8 TB SN850X, an 'E' version with tweaked firmware is likely to be present in the 16 TB Desk Drive.

The 16 TB portable SSD in the SanDisk Extreme housing was a technology demonstration. It is definitely the highest capacity bus-powered portable SSD demonstrated by any vendor at any trade show thus far. Given the 16 TB Desk Drive's imminent market introduction, it is just a matter of time before the technology demonstration of the bus-powered version becomes a retail reality.
Storage
The CXL consortium has had a regular presence at FMS (which rechristened itself from 'Flash Memory Summit' to the 'Future of Memory and Storage' this year). Back at FMS 2022, the company had announced v3.0 of the CXL specifications. This was followed by CXL 3.1's introduction at Supercomputing 2023. Having started off as a host to device interconnect standard, it had slowly subsumed other competing standards such as OpenCAPI and Gen-Z. As a result, the specifications started to encompass a wide variety of use-cases by building a protocol on top of the the ubiquitous PCIe expansion bus. The CXL consortium comprises of heavyweights such as AMD and Intel, as well as a large number of startup companies attempting to play in different segments on the device side. At FMS 2024, CXL had a prime position in the booth demos of many vendors.
The migration of server platforms from DDR4 to DDR5, along with the rise of workloads demanding large RAM capacity (but not particularly sensitive to either memory bandwidth or latency), has opened up memory expansion modules as one of the first set of widely available CXL devices. Over the last couple of years, we have had product announcements from Samsung and Micron in this area.
At FMS 2024, SK hynix was showing off their DDR5-based CMM-DDR5 CXL memory module with a 128 GB capacity. The company was also detailing their associated Heterogeneous Memory Software Development Kit (HMSDK) - a set of libraries and tools at both the kernel and user levels aimed at increasing the ease of use of CXL memory. This is achieved in part by considering the memory pyramid / hierarchy and relocating the data between the server's main memory (DRAM) and the CXL device based on usage frequency.
The CMM-DDR5 CXL memory module comes in the SDFF form-factor (E3.S 2T) with a PCIe 3.0 x8 host interface. The internal memory is based on 1α technology DRAM, and the device promises DDR5-class bandwidth and latency within a single NUMA hop. As these memory modules are meant to be used in datacenters and enterprises, the firmware includes features for RAS (reliability, availability, and serviceability) along with secure boot and other management features.
SK hynix was also demonstrating Niagara 2.0 - a hardware solution (currently based on FPGAs) to enable memory pooling and sharing - i.e, connecting multiple CXL memories to allow different hosts (CPUs and GPUs) to optimally share their capacity. The previous version only allowed capacity sharing, but the latest version enables sharing of data also. SK hynix had presented these solutions at the CXL DevCon 2024 earlier this year, but some progress seems to have been made in finalizing the specifications of the CMM-DDR5 at FMS 2024.
Micron had unveiled the CZ120 CXL Memory Expansion Module last year based on the Microchip SMC 2000 series CXL memory controller. At FMS 2024, Micron and Microchip had a demonstration of the module on a Granite Rapids server.
Additional insights into the SMC 2000 controller were also provided.
The CXL memory controller also incorporates DRAM die failure handling, and Microchip also provides diagnostics and debug tools to analyze failed modules. The memory controller also supports ECC, which forms part of the enterprise... Storage
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
At FMS 2024, the technological requirements from the storage and memory subsystem took center stage. Both SSD and controller vendors had various demonstrations touting their suitability for different stages of the AI data pipeline - ingestion, preparation, training, checkpointing, and inference. Vendors like Solidigm have different types of SSDs optimized for different stages of the pipeline. At the same time, controller vendors have taken advantage of one of the features introduced recently in the NVM Express standard - Flexible Data Placement (FDP).
FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.
Silicon Motion's MonTitan Gen 5 Enterprise SSD Platform was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.
At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.
Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.
Storage

Coming out of the dark times that preceded the launch of AMD's Zen CPU architecture in 2017, to say that AMD has turned things around on the back of Zen would be an understatement. Ever since AMD launched its first Zen-based Ryzen and EPYC processors for client and server computers, it has been consistently gaining x86 market share, growing from a bit player to a respectable rival to Intel (and all at Intel's expense).
The first quarter of this year was no exception, according to Mercury Research, as the company achieved record high unit shares on x86 desktop and x86 server CPU markets due to success of its Ryzen 8000-series client products and 4th Generation EPYC processors.
"Mercury noted in their first quarter report that AMD gained significant server and client revenue share driven by growing demand for 4th Gen EPYC and Ryzen 8000 series processors," a statement by AMD reads.
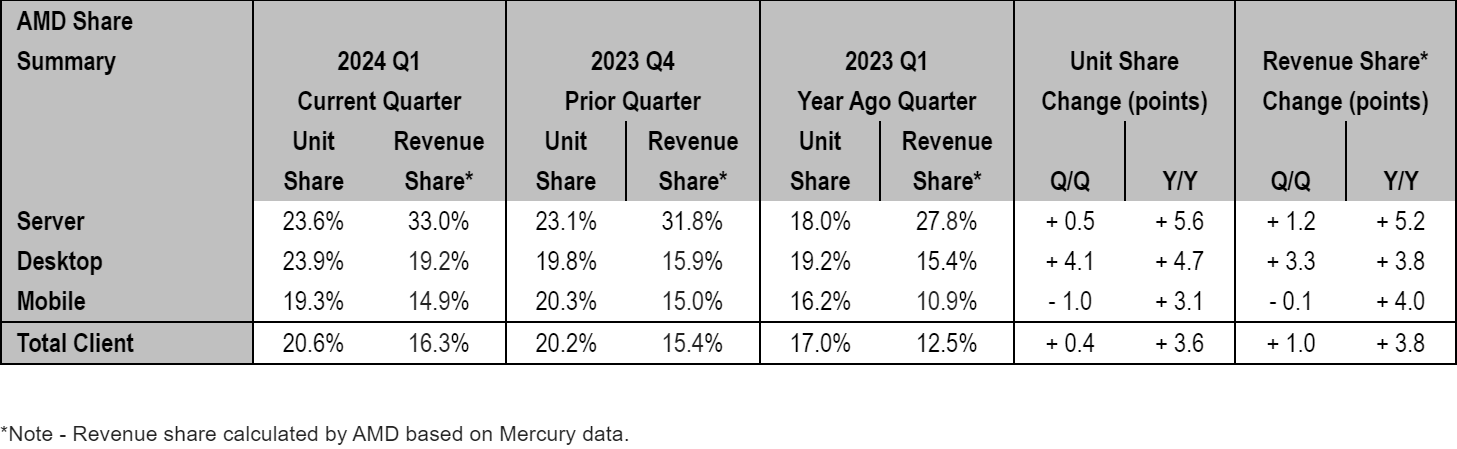
Desktops, particularly DIY desktops, have always been AMD's strongest market. After the company launched its Ryzen processors in 2017, it doubled its presence in desktops in just three years. But in the recent years the company had to prioritize production of more expensive CPUs for datacenters, which lead to some erosion of its desktop and mobile market shares.
As the company secured more capacity at TSMC, it started to gradually increase production of desktop processors. In Q4 last year it introduced its Zen 4-based Ryzen 8000/Ryzen 8000 Pro processors for mainstream desktops, which appeared to be pretty popular with PC makers.
As a result of this and other factors, AMD increased unit sales of its desktop CPUs by 4.7% year-over-year in Q1 2024 and its market share achieved 23.9%, which is the highest desktop CPU market share the company commanded in over a decade. Interestingly, AMD does not attribute its success on the desktop front to any particular product or product family, which implies that there are multiple factors at play.
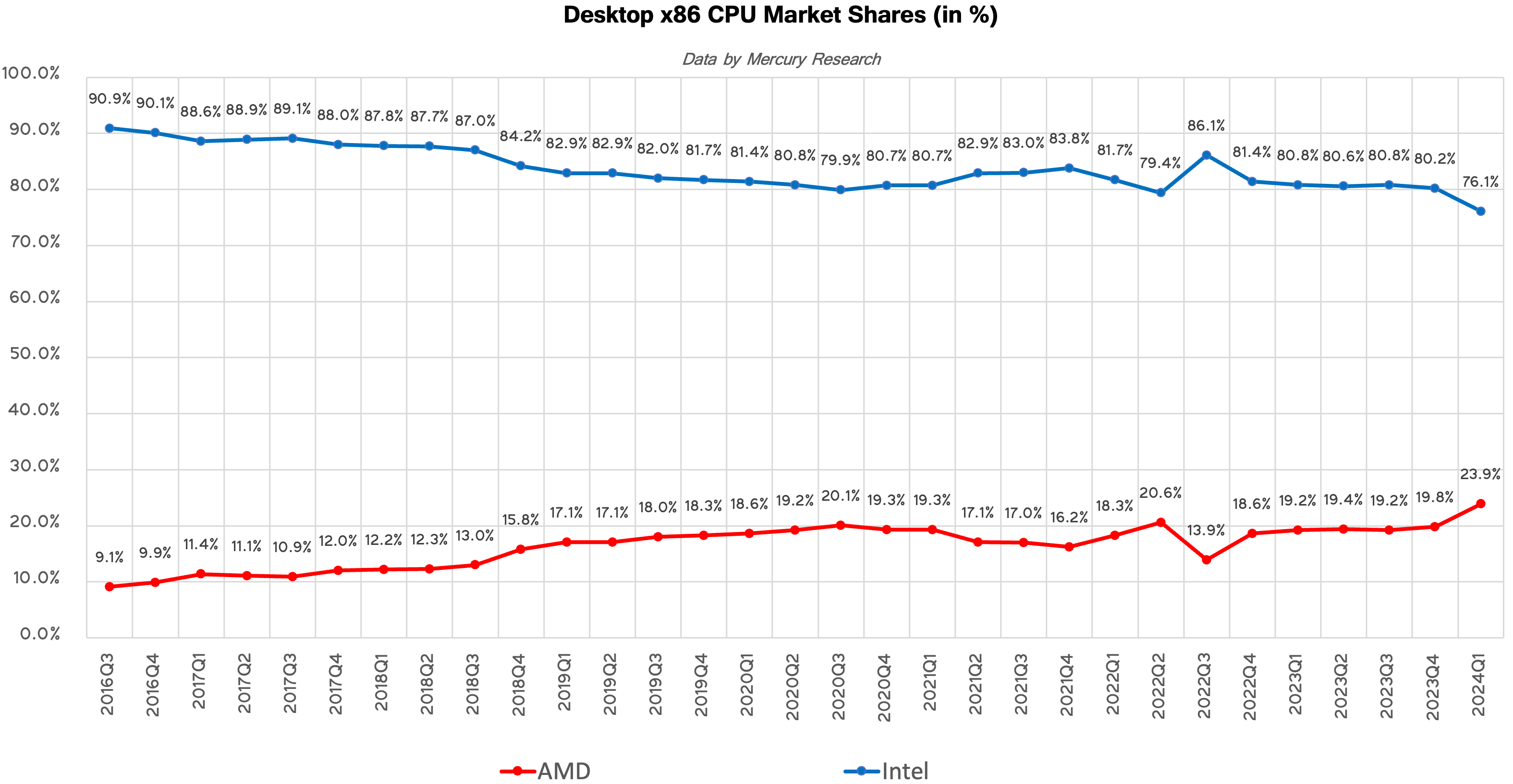
AMD has been gradually regaining its share inside laptops for about 1.5 years now and sales of its Zen 4-based Ryzen 7040-series processors were quite strong in Q3 2023 and Q4 2023, when the company's unit share increased to 19.5% and 20.3%, respectively, as AMD-based notebook platforms ramped up. By contrast, Intel's Core Ultra 'Meteor Lake' powered machines only began to hit retail shelves in Q4'23, which affected sales of its processors for laptops.
In the first quarter AMD's unit share on the market of CPUs for notebooks decreased to 19.3%, down 1% sequentially. Meanwhile, the company still demonstrated significant year-over-year unit share increase of 3.1% and revenue share increase of 4%, which signals rising average selling price of AMD's latest Ryzen processors for mobile PCs.
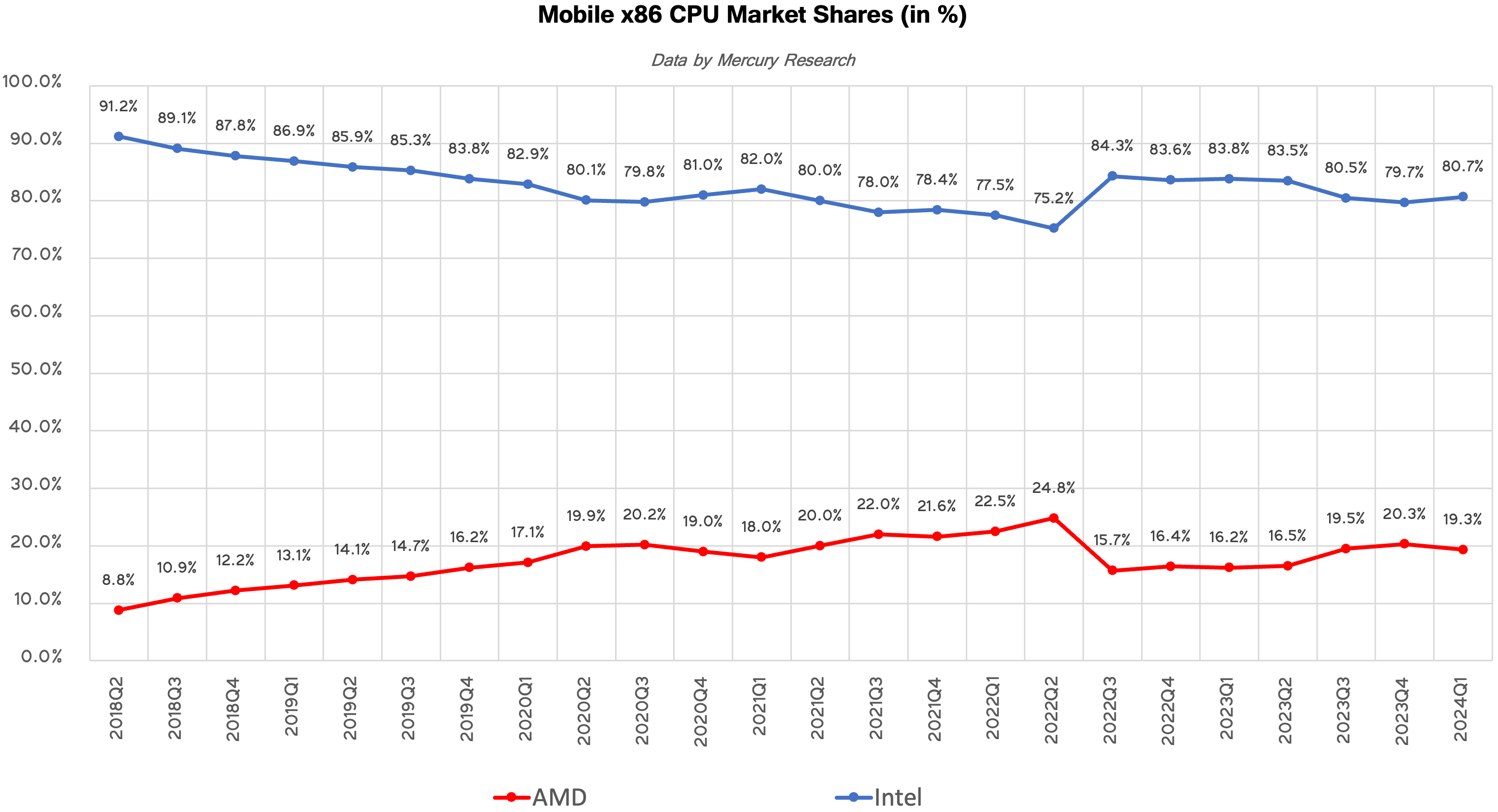
Overall, Intel remained the dominant force in client PC sales in the first quarter of 2024, with a 79.4% market share, leaving 20.6% for AMD. This is not particularly surprising given how strong and diverse Intel's client products lineup is. Even with continued success, it will take AMD years to grow sales by enough to completely flip the market.
But AMD actually gained a 0.3% unit share sequentially and a 3.6% unit share year-over year. Notably, however, AMD's revenue share of client PC market is significantly lower than its unit share (16.3% vs 20.6%), so the company is still somewhat pigeonholed into selling more budg... CPUs
The CXL consortium has had a regular presence at FMS (which rechristened itself from 'Flash Memory Summit' to the 'Future of Memory and Storage' this year). Back at FMS 2022, the company had announced v3.0 of the CXL specifications. This was followed by CXL 3.1's introduction at Supercomputing 2023. Having started off as a host to device interconnect standard, it had slowly subsumed other competing standards such as OpenCAPI and Gen-Z. As a result, the specifications started to encompass a wide variety of use-cases by building a protocol on top of the the ubiquitous PCIe expansion bus. The CXL consortium comprises of heavyweights such as AMD and Intel, as well as a large number of startup companies attempting to play in different segments on the device side. At FMS 2024, CXL had a prime position in the booth demos of many vendors.
The migration of server platforms from DDR4 to DDR5, along with the rise of workloads demanding large RAM capacity (but not particularly sensitive to either memory bandwidth or latency), has opened up memory expansion modules as one of the first set of widely available CXL devices. Over the last couple of years, we have had product announcements from Samsung and Micron in this area.
At FMS 2024, SK hynix was showing off their DDR5-based CMM-DDR5 CXL memory module with a 128 GB capacity. The company was also detailing their associated Heterogeneous Memory Software Development Kit (HMSDK) - a set of libraries and tools at both the kernel and user levels aimed at increasing the ease of use of CXL memory. This is achieved in part by considering the memory pyramid / hierarchy and relocating the data between the server's main memory (DRAM) and the CXL device based on usage frequency.
The CMM-DDR5 CXL memory module comes in the SDFF form-factor (E3.S 2T) with a PCIe 3.0 x8 host interface. The internal memory is based on 1α technology DRAM, and the device promises DDR5-class bandwidth and latency within a single NUMA hop. As these memory modules are meant to be used in datacenters and enterprises, the firmware includes features for RAS (reliability, availability, and serviceability) along with secure boot and other management features.
SK hynix was also demonstrating Niagara 2.0 - a hardware solution (currently based on FPGAs) to enable memory pooling and sharing - i.e, connecting multiple CXL memories to allow different hosts (CPUs and GPUs) to optimally share their capacity. The previous version only allowed capacity sharing, but the latest version enables sharing of data also. SK hynix had presented these solutions at the CXL DevCon 2024 earlier this year, but some progress seems to have been made in finalizing the specifications of the CMM-DDR5 at FMS 2024.
Micron had unveiled the CZ120 CXL Memory Expansion Module last year based on the Microchip SMC 2000 series CXL memory controller. At FMS 2024, Micron and Microchip had a demonstration of the module on a Granite Rapids server.
Additional insights into the SMC 2000 controller were also provided.
The CXL memory controller also incorporates DRAM die failure handling, and Microchip also provides diagnostics and debug tools to analyze failed modules. The memory controller also supports ECC, which forms part of the enterprise... Storage

Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's.
The CXL consortium has had a regular presence at FMS (which rechristened itself from 'Flash Memory Summit' to the 'Future of Memory and Storage' this year). Back at FMS 2022, the company had announced v3.0 of the CXL specifications. This was followed by CXL 3.1's introduction at Supercomputing 2023. Having started off as a host to device interconnect standard, it had slowly subsumed other competing standards such as OpenCAPI and Gen-Z. As a result, the specifications started to encompass a wide variety of use-cases by building a protocol on top of the the ubiquitous PCIe expansion bus. The CXL consortium comprises of heavyweights such as AMD and Intel, as well as a large number of startup companies attempting to play in different segments on the device side. At FMS 2024, CXL had a prime position in the booth demos of many vendors.
The migration of server platforms from DDR4 to DDR5, along with the rise of workloads demanding large RAM capacity (but not particularly sensitive to either memory bandwidth or latency), has opened up memory expansion modules as one of the first set of widely available CXL devices. Over the last couple of years, we have had product announcements from Samsung and Micron in this area.
At FMS 2024, SK hynix was showing off their DDR5-based CMM-DDR5 CXL memory module with a 128 GB capacity. The company was also detailing their associated Heterogeneous Memory Software Development Kit (HMSDK) - a set of libraries and tools at both the kernel and user levels aimed at increasing the ease of use of CXL memory. This is achieved in part by considering the memory pyramid / hierarchy and relocating the data between the server's main memory (DRAM) and the CXL device based on usage frequency.
The CMM-DDR5 CXL memory module comes in the SDFF form-factor (E3.S 2T) with a PCIe 3.0 x8 host interface. The internal memory is based on 1α technology DRAM, and the device promises DDR5-class bandwidth and latency within a single NUMA hop. As these memory modules are meant to be used in datacenters and enterprises, the firmware includes features for RAS (reliability, availability, and serviceability) along with secure boot and other management features.
SK hynix was also demonstrating Niagara 2.0 - a hardware solution (currently based on FPGAs) to enable memory pooling and sharing - i.e, connecting multiple CXL memories to allow different hosts (CPUs and GPUs) to optimally share their capacity. The previous version only allowed capacity sharing, but the latest version enables sharing of data also. SK hynix had presented these solutions at the CXL DevCon 2024 earlier this year, but some progress seems to have been made in finalizing the specifications of the CMM-DDR5 at FMS 2024.
Micron had unveiled the CZ120 CXL Memory Expansion Module last year based on the Microchip SMC 2000 series CXL memory controller. At FMS 2024, Micron and Microchip had a demonstration of the module on a Granite Rapids server.
Additional insights into the SMC 2000 controller were also provided.
The CXL memory controller also incorporates DRAM die failure handling, and Microchip also provides diagnostics and debug tools to analyze failed modules. The memory controller also supports ECC, which forms part of the enterprise... Storage
It is with great sadness that I find myself penning the hardest news post I’ve ever needed to write here at AnandTech. After over 27 years of covering the wide – and wild – world of computing hardware, today is AnandTech’s final day of publication.
For better or worse, we’ve reached the end of a long journey – one that started with a review of an AMD processor, and has ended with the review of an AMD processor. It’s fittingly poetic, but it is also a testament to the fact that we’ve spent the last 27 years doing what we love, covering the chips that are the lifeblood of the computing industry.
A lot of things have changed in the last quarter-century – in 1997 NVIDIA had yet to even coin the term “GPU” – and we’ve been fortunate to watch the world of hardware continue to evolve over the time period. We’ve gone from boxy desktop computers and laptops that today we’d charitably classify as portable desktops, to pocket computers where even the cheapest budget device puts the fastest PC of 1997 to shame.
The years have also brought some monumental changes to the world of publishing. AnandTech was hardly the first hardware enthusiast website, nor will we be the last. But we were fortunate to thrive in the past couple of decades, when so many of our peers did not, thanks to a combination of hard work, strategic investments in people and products, even more hard work, and the support of our many friends, colleagues, and readers.
Still, few things last forever, and the market for written tech journalism is not what it once was – nor will it ever be again. So, the time has come for AnandTech to wrap up its work, and let the next generation of tech journalists take their place within the zeitgeist.
It has been my immense privilege to write for AnandTech for the past 19 years – and to manage it as its editor-in-chief for the past decade. And while I carry more than a bit of remorse in being AnandTech’s final boss, I can at least take pride in everything we’ve accomplished over the years, whether it’s lauding some legendary products, writing technology primers that still remain relevant today, or watching new stars rise in expected places. There is still more that I had wanted AnandTech to do, but after 21,500 articles, this was a good start.
And while the AnandTech staff is riding off into the sunset, I am happy to report that the site itself won’t be going anywhere for a while. Our publisher, Future PLC, will be keeping the AnandTech website and its many articles live indefinitely. So that all of the content we’ve created over the years remains accessible and citable. Even without new articles to add to the collection, I expect that many of the things we’ve written over the past couple of decades will remain relevant for years to come – and remain accessible just as long.
The AnandTech Forums will also continue to be operated by Future’s community team and our dedicated troop of moderators. With forum threads going back to 1999 (and some active members just as long), the forums have a history almost as long and as storied as AnandTech itself (wounded monitor children, anyone?). So even when AnandTech is no longer publishing articles, we’ll still have a place for everyone to talk about the latest in technology – and have those discussions last longer than 48 hours.
Finally, for everyone who still needs their technical writing fix, our formidable opposition of the last 27 years and fellow Future brand, Tom’s Hardware, is continuing to cover the world of technology. There are a couple of familiar AnandTech faces already over there providing their accumulated expertise, and the site will continue doing its best to provide a written take on technology news.
As I look back on everything AnandTech has accomplished over the past 27 years, there are more than a few people, groups, and companies that I would like to thank on behalf of both myself and AnandTech as a whole.
First and foremost, I cannot thank enough all the editors who have worked for AnandTech over the years. T... Site Updates
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage.</p>
<p>FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.</p>
<p>Silicon Motion's <a href="https://www.anandtech.com/show/17512/silicon-motion-sm8366-montitan-ssd-platform">MonTitan Gen 5 Enterprise SSD Platform</a> was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.</p>
<p align="center"><a href="https://www.anandtech.com/show/21522/silicon-motion-demonstrates-flexible-data-placement-on-montitan-gen-5-enterprise-ssd-platform"><img alt="" src="https://images.anandtech.com/doci/21522/mid-page_575px.jpg" /></a></p>
<p>At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.</p>
<p>Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.</p>
</p> Storage){kind=link}
.</p>
<p>FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.</p>
<p>Silicon Motion's <a href="https://www.anandtech.com/show/17512/silicon-motion-sm8366-montitan-ssd-platform">MonTitan Gen 5 Enterprise SSD Platform</a> was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.</p>
<p align="center"><a href="https://www.anandtech.com/show/21522/silicon-motion-demonstrates-flexible-data-placement-on-montitan-gen-5-enterprise-ssd-platform"><img alt="" src="https://images.anandtech.com/doci/21522/mid-page_575px.jpg" /></a></p>
<p>At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.</p>
<p>Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.</p>
</p> Storage){kind=link}
.</p>
<p>FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.</p>
<p>Silicon Motion's <a href="https://www.anandtech.com/show/17512/silicon-motion-sm8366-montitan-ssd-platform">MonTitan Gen 5 Enterprise SSD Platform</a> was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.</p>
<p align="center"><a href="https://www.anandtech.com/show/21522/silicon-motion-demonstrates-flexible-data-placement-on-montitan-gen-5-enterprise-ssd-platform"><img alt="" src="https://images.anandtech.com/doci/21522/mid-page_575px.jpg" /></a></p>
<p>At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.</p>
<p>Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.</p>
</p> Storage | https://compbuddey.blogspot.com/2025/07/silicon-motion-demonstrates-flexible_63.html){kind=link}
.</p>
<p>FDP involves the host providing information / hints about the areas where the controller could place the incoming write data in order to reduce the write amplification. These hints are generated based on specific block sizes advertised by the device. The feature is completely backwards-compatible, with non-FDP hosts working just as before with FDP-enabled SSDs, and vice-versa.</p>
<p>Silicon Motion's <a href="https://www.anandtech.com/show/17512/silicon-motion-sm8366-montitan-ssd-platform">MonTitan Gen 5 Enterprise SSD Platform</a> was announced back in 2022. Since then, Silicon Motion has been touting the flexibility of the platform, allowing its customers to incorporate their own features as part of the customization process. This approach is common in the enterprise space, as we have seen with Marvell's Bravera SC5 SSD controller in the DapuStor SSDs and Microchip's Flashtec controllers in the Longsys FORESEE enterprise SSDs.</p>
<p align="center"><a href="https://www.anandtech.com/show/21522/silicon-motion-demonstrates-flexible-data-placement-on-montitan-gen-5-enterprise-ssd-platform"><img alt="" src="https://images.anandtech.com/doci/21522/mid-page_575px.jpg" /></a></p>
<p>At FMS 2024, the company was demonstrating the advantages of flexible data placement by allowing a single QLC SSD based on their MonTitan platform to take part in different stages of the AI data pipeline while maintaining the required quality of service (minimum bandwidth) for each process. The company even has a trademarked name (PerformaShape) for the firmware feature in the controller that allows the isolation of different concurrent SSD accesses (from different stages in the AI data pipeline) to guarantee this QoS. Silicon Motion claims that this scheme will enable its customers to get the maximum write performance possible from QLC SSDs without negatively impacting the performance of other types of accesses.</p>
<p>Silicon Motion and Phison have market leadership in the client SSD controller market with similar approaches. However, their enterprise SSD controller marketing couldn't be more different. While Phison has gone in for a turnkey solution with their Gen 5 SSD platform (to the extent of not adopting the white label route for this generation, and instead opting to get the SSDs qualified with different cloud service providers themselves), Silicon Motion is opting for a different approach. The flexibility and customization possibilities can make platforms like the MonTitan appeal to flash array vendors.</p>
</p> Storage&body=https://compbuddey.blogspot.com/2025/07/silicon-motion-demonstrates-flexible_63.html){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 Comments