Kioxia Demonstrates RAID Offload Scheme for NVMe Drives <p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img src="https://images.anandtech.com/doci/21523/raidoff-carousel_575px.jpg" alt="" /></a></p><p><p>At FMS 2024, Kioxia had a proof-of-concept demonstration of their proposed a new RAID offload methodology for enterprise SSDs. The impetus for this is quite clear: as SSDs get faster in each generation, RAID arrays have a major problem of maintaining (and scaling up) performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.</p>
<p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img alt="" src="https://images.anandtech.com/doci/21523/raidoff-mid_575px.png" /></a></p>
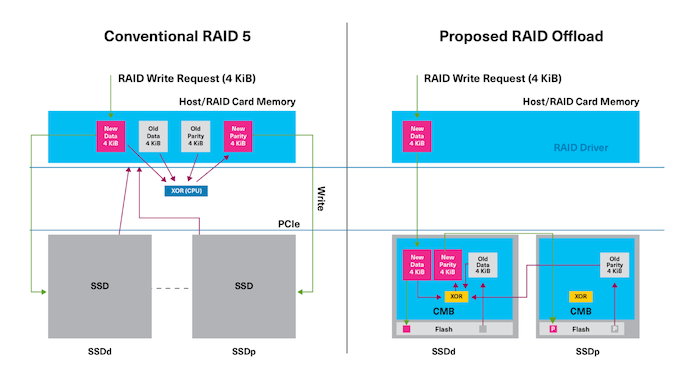
<p>Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.</p>
<p>In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.</p>
<p>Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.</p>
</p> Storage
Kioxia Demonstrates RAID Offload Scheme for NVMe Drives
At FMS 2024, Kioxia had a proof-of-concept demonstration of their proposed a new RAID offload methodology for enterprise SSDs. The impetus for this is quite clear: as SSDs get faster in each generation, RAID arrays have a major problem of maintaining (and scaling up) performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.
Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.
In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.
Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.



 performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.</p>
<p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img alt="" src="https://images.anandtech.com/doci/21523/raidoff-mid_575px.png" /></a></p>
<p>Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.</p>
<p>In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.</p>
<p>Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.</p>
</p> Storage){kind=link}
 performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.</p>
<p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img alt="" src="https://images.anandtech.com/doci/21523/raidoff-mid_575px.png" /></a></p>
<p>Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.</p>
<p>In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.</p>
<p>Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.</p>
</p> Storage){kind=link}
 performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.</p>
<p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img alt="" src="https://images.anandtech.com/doci/21523/raidoff-mid_575px.png" /></a></p>
<p>Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.</p>
<p>In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.</p>
<p>Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.</p>
</p> Storage | https://compbuddey.blogspot.com/2025/07/kioxia-demonstrates-raid-offload-scheme_24.html){kind=link}
 performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.</p>
<p align="center"><a href="https://www.anandtech.com/show/21523/kioxia-demonstrates-raid-offload-scheme-for-nvme-drives"><img alt="" src="https://images.anandtech.com/doci/21523/raidoff-mid_575px.png" /></a></p>
<p>Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.</p>
<p>In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.</p>
<p>Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.</p>
</p> Storage&body=https://compbuddey.blogspot.com/2025/07/kioxia-demonstrates-raid-offload-scheme_24.html){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 Comments