
The DeepCool PX850G 850W PSU Review: Less Than Quiet, More Than Capable
DeepCool is one of the few veterans in the PC power & cooling components field still active today. The Chinese company was first founded in 1996 and initially produced only coolers and cooling accessories, but quickly diversified into the PC Case and power supply unit (PSU) markets. To this day, DeepCool stays almost entirely focused on PC power & cooling products, with input devices and mousepads being their latest diversification attempt.
Today's review turns the spotlight toward DeepCool’s PSUs and, more specifically, the PX850G 850W ATX 3.0 PSU, which currently is their most popular power supply. The PX850G is engineered to balance all-around performance with reliability and cost, all while providing ATX 3.0 compliance. It is based on a highly popular high-output platform but, strangely, DeepCool rated the PX850G for operation up to 40°C.
Cases/Cooling/PSUsPosted by The Techinical Support

Intel Sells Its Arm Shares, Reduces Stakes in Other Companies 
Intel has divested its entire stake in Arm Holdings during the second quarter, raising approximately $147 million. Alongside this, Intel sold its stake in cybersecurity firm ZeroFox and reduced its holdings in Astera Labs, all as part of a broader effort to manage costs and recover cash amid significant financial challenges.
The sale of Intel's 1.18 million shares in Arm Holdings, as reported in a recent SEC filing, comes at a time when the company is struggling with substantial financial losses. Despite the $147 million generated from the sale, Intel reported a $120 million net loss on its equity investments for the quarter, which is a part of a larger $1.6 billion loss that Intel faced during this period.
In addition to selling its stake in Arm, Intel also exited its investment in ZeroFox and reduced its involvement with Astera Labs, a company known for developing connectivity platforms for enterprise hardware. These moves are in line with Intel's strategy to reduce costs and stabilize its financial position as it faces ongoing market challenges.
Despite the divestment, Intel's past investment in Arm was likely driven by strategic considerations. Arm Holdings is a significant force in the semiconductor industry, with its designs powering most mobile devices, and, for obvious reasons, Intel would like to address these. Intel and Arm are also collaborating on datacenter platforms tailored for Intel's 18A process technology. Additionally, Arm might view Intel as a potential licensee for its technologies and a valuable partner for other companies that license Arm's designs.
Intel's investment in Astera Labs was also a strategic one as the company probably wanted to secure steady supply of smart retimers, smart cable modems, and CXL memory controller, which are used in volumes in datacenters and Intel is certainly interested in selling as many datacenter CPUs as possible.
Intel's financial struggles were highlighted earlier this month when the company released a disappointing earnings report, which led to a 33% drop in its stock value, erasing billions of dollars of capitalization. To counter these difficulties, Intel announced plans to cut 15,000 jobs and implement other expense reductions. The company has also suspended its dividend, signaling the depth of its efforts to conserve cash and focus on recovery. When it comes to divestment of Arm stock, the need for immediate financial stabilization has presumably taken precedence, leading to the decision.
CPUs

Kioxia Details BiCS 8 NAND at FMS 2024: 218 Layers With Superior Scaling 
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.

Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.

The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage

G.Skill Intros Low Latency DDR5 Memory Modules: CL30 at 6400 MT/s 
G.Skill on Tuesday introduced its ultra-low-latency DDR5-6400 memory modules that feature a CAS latency of 30 clocks, which appears to be the industry's most aggressive timings yet for DDR5-6400 sticks. The modules will be available for both AMD and Intel CPU-based systems.
With every new generation of DDR memory comes an increase in data transfer rates and an extension of relative latencies. While for the vast majority of applications, the increased bandwidth offsets the performance impact of higher timings, there are applications that favor low latencies. However, shrinking latencies is sometimes harder than increasing data transfer rates, which is why low-latency modules are rare.
Nonetheless, G.Skill has apparently managed to cherry-pick enough DDR5 memory chips and build appropriate printed circuit boards to produce DDR5-6400 modules with CL30 timings, which are substantially lower than the CL46 timings recommended by JEDEC for this speed bin. This means that while JEDEC-standard modules have an absolute latency of 14.375 ns, G.Skill's modules can boast a latency of just 9.375 ns – an approximately 35% decrease.
G.Skill's DDR5-6400 CL30 39-39-102 modules have a capacity of 16 GB and will be available in 32 GB dual-channel kits, though the company does not disclose voltages, which are likely considerably higher than those standardized by JEDEC.
The company plans to make its DDR5-6400 modules available both for AMD systems with EXPO profiles (Trident Z5 Neo RGB and Trident Z5 Royal Neo) and for Intel-powered PCs with XMP 3.0 profiles (Trident Z5 RGB and Trident Z5 Royal). For AMD AM5 systems that have a practical limitation of 6000 MT/s – 6400 MT/s for DDR5 memory (as this is roughly as fast as AMD's Infinity Fabric can operate at with a 1:1 ratio), the new modules will be particularly beneficial for AMD's Ryzen 7000 and Ryzen 9000-series processors.
G.Skill notes that since its modules are non-standard, they will not work with all systems but will operate on high-end motherboards with properly cooled CPUs.
The new ultra-low-latency memory kits will be available worldwide from G.Skill's partners starting in late August 2024. The company did not disclose the pricing of these modules, but since we are talking about premium products that boast unique specifications, they are likely to be priced accordingly.
Memory


Intel Sells Its Arm Shares, Reduces Stakes in Other Companies
Intel has divested its entire stake in Arm Holdings during the second quarter, raising approximately $147 million. Alongside this, Intel sold its stake in cybersecurity firm ZeroFox and reduced its holdings in Astera Labs, all as part of a broader effort to manage costs and recover cash amid significant financial challenges.
The sale of Intel's 1.18 million shares in Arm Holdings, as reported in a recent SEC filing, comes at a time when the company is struggling with substantial financial losses. Despite the $147 million generated from the sale, Intel reported a $120 million net loss on its equity investments for the quarter, which is a part of a larger $1.6 billion loss that Intel faced during this period.
In addition to selling its stake in Arm, Intel also exited its investment in ZeroFox and reduced its involvement with Astera Labs, a company known for developing connectivity platforms for enterprise hardware. These moves are in line with Intel's strategy to reduce costs and stabilize its financial position as it faces ongoing market challenges.
Despite the divestment, Intel's past investment in Arm was likely driven by strategic considerations. Arm Holdings is a significant force in the semiconductor industry, with its designs powering most mobile devices, and, for obvious reasons, Intel would like to address these. Intel and Arm are also collaborating on datacenter platforms tailored for Intel's 18A process technology. Additionally, Arm might view Intel as a potential licensee for its technologies and a valuable partner for other companies that license Arm's designs.
Intel's investment in Astera Labs was also a strategic one as the company probably wanted to secure steady supply of smart retimers, smart cable modems, and CXL memory controller, which are used in volumes in datacenters and Intel is certainly interested in selling as many datacenter CPUs as possible.
Intel's financial struggles were highlighted earlier this month when the company released a disappointing earnings report, which led to a 33% drop in its stock value, erasing billions of dollars of capitalization. To counter these difficulties, Intel announced plans to cut 15,000 jobs and implement other expense reductions. The company has also suspended its dividend, signaling the depth of its efforts to conserve cash and focus on recovery. When it comes to divestment of Arm stock, the need for immediate financial stabilization has presumably taken precedence, leading to the decision.
CPUs
Kioxia Details BiCS 8 NAND at FMS 2024: 218 Layers With Superior Scaling
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
G.Skill Intros Low Latency DDR5 Memory Modules: CL30 at 6400 MT/s
G.Skill on Tuesday introduced its ultra-low-latency DDR5-6400 memory modules that feature a CAS latency of 30 clocks, which appears to be the industry's most aggressive timings yet for DDR5-6400 sticks. The modules will be available for both AMD and Intel CPU-based systems.
With every new generation of DDR memory comes an increase in data transfer rates and an extension of relative latencies. While for the vast majority of applications, the increased bandwidth offsets the performance impact of higher timings, there are applications that favor low latencies. However, shrinking latencies is sometimes harder than increasing data transfer rates, which is why low-latency modules are rare.
Nonetheless, G.Skill has apparently managed to cherry-pick enough DDR5 memory chips and build appropriate printed circuit boards to produce DDR5-6400 modules with CL30 timings, which are substantially lower than the CL46 timings recommended by JEDEC for this speed bin. This means that while JEDEC-standard modules have an absolute latency of 14.375 ns, G.Skill's modules can boast a latency of just 9.375 ns – an approximately 35% decrease.
G.Skill's DDR5-6400 CL30 39-39-102 modules have a capacity of 16 GB and will be available in 32 GB dual-channel kits, though the company does not disclose voltages, which are likely considerably higher than those standardized by JEDEC.
The company plans to make its DDR5-6400 modules available both for AMD systems with EXPO profiles (Trident Z5 Neo RGB and Trident Z5 Royal Neo) and for Intel-powered PCs with XMP 3.0 profiles (Trident Z5 RGB and Trident Z5 Royal). For AMD AM5 systems that have a practical limitation of 6000 MT/s – 6400 MT/s for DDR5 memory (as this is roughly as fast as AMD's Infinity Fabric can operate at with a 1:1 ratio), the new modules will be particularly beneficial for AMD's Ryzen 7000 and Ryzen 9000-series processors.
G.Skill notes that since its modules are non-standard, they will not work with all systems but will operate on high-end motherboards with properly cooled CPUs.
The new ultra-low-latency memory kits will be available worldwide from G.Skill's partners starting in late August 2024. The company did not disclose the pricing of these modules, but since we are talking about premium products that boast unique specifications, they are likely to be priced accordingly.
Memory

NVIDIA Closes Above $135, Becomes World’s Most Valuable Company 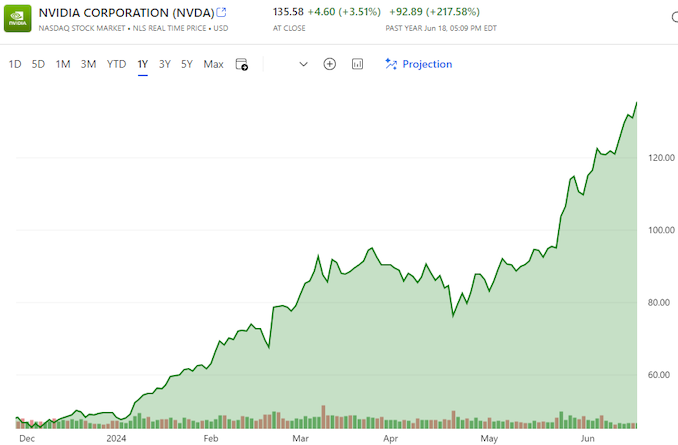
Thanks to the success of the burgeoning market for AI accelerators, NVIDIA has been on a tear this year. And the only place that’s even more apparent than the company’s rapidly growing revenues is in the company’s stock price and market capitalization. After breaking into the top 5 most valuable companies only earlier this year, NVIDIA has reached the apex of Wall Street, closing out today as the world’s most valuable company.
With a closing price of $135.58 on a day that saw NVIDIA’s stock pop up another 3.5%, NVIDIA has topped both Microsoft and Apple in valuation, reaching a market capitalization of $3.335 trillion. This follows a rapid rise in the company’s stock price, which has increased by 47% in the last month alone – particularly on the back of NVIDIA’s most recent estimates-beating earnings report – as well as a recent 10-for-1 stock split. And looking at the company’s performance over a longer time period, NVIDIA’s stock jumped a staggering 218% over the last year, or a mere 3,474% over the last 5 years.
NVIDIA’s ascension continues a trend over the last several years of tech companies all holding the top spots in the market capitalization rankings. Though this is the first time in quite a while that the traditional tech leaders of Apple and Microsoft have been pushed aside.
| Market Capitalization Rankings | ||
| Market Cap | Stock Price | |
| NVIDIA | $3.335T | $135.58 |
| Microsoft | $3.317T | $446.34 |
| Apple | $3.285T | $214.29 |
| Alphabet | $2.170T | $176.45 |
| Amazon | $1.902T | $182.81 |
Driving the rapid growth of NVIDIA and its market capitalization has been demand for AI accelerators from NVIDIA, particularly the company’s server-grade H100, H200, and GH200 accelerators for AI training. As the demand for these products has spiked, NVIDIA has been scaling up accordingly, repeatedly beating market expectations for how many of the accelerators they can ship – and what price they can charge. And despite all that growth, orders for NVIDIA’s high-end accelerators are still backlogged, underscoring how NVIDIA still isn’t meeting the full demands of hyperscalers and other enterprises.
Consequently, NVIDIA’s stock price and market capitalization have been on a tear on the basis of these future expectations. With a price-to-earnings (P/E) ratio of 76.7 – more than twice that of Microsoft or Apple – NVIDIA is priced more like a start-up than a 30-year-old tech company. But then it goes without saying that most 30-year-old tech companies aren’t tripling their revenue in a single year, placing NVIDIA in a rather unique situation at this time.
Like the stock market itself, market capitalizations are highly volatile. And historically speaking, it’s far from guaranteed that NVIDIA will be able to hold the top spot for long, never mind day-to-day fluctuations. NVIDIA, Apple, and Microsoft’s valuations are all within $50 billion (1.%) of each other, so for the moment at least, it’s still a tight race between all three companies. But no matter what happens from here, NVIDIA gets the exceptionally rare claim of having been the most valuable company in the world at some point.
(Carousel image courtesy MSN Money)
GPUs



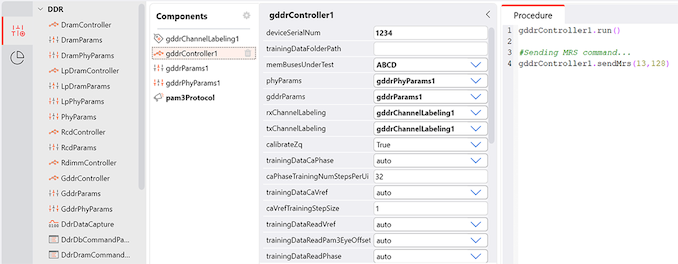
Introspect Intros GDDR7 Test System For Fast GDDR7 GPU Design Bring Up 
Introspect this week introduced its M5512 GDDR7 memory test system, which is designed for testing GDDR7 memory controllers, physical interface, and GDDR7 SGRAM chips. The tool will enable memory and processor manufacturers to verify that their products perform as specified by the standard.
One of the crucial phases of a processor design bring up is testing its standard interfaces, such as PCIe, DisplayPort, or GDDR is to ensure that they behave as specified both logically and electrically and achieve designated performance. Introspect's M5512 GDDR7 memory test system is designed to do just that: test new GDDR7 memory devices, troubleshoot protocol issues, assess signal integrity, and conduct comprehensive memory read/write stress tests.
The product will be quite useful for designers of GPUs/SoCs, graphics cards, PCs, network equipment and memory chips, which will speed up development of actual products that rely on GDDR7 memory. For now, GPU and SoC designers as well as memory makers use highly-custom setups consisting of many tools to characterize signal integrity as well as conduct detailed memory read/write functional stress testing, which are important things at this phase of development. But usage of a single tool greatly speeds up all the processes and gives a more comprehensive picture to specialists.
The M5512 GDDR7 Memory Test System is a desktop testing and measurement device that is equippped with 72 pins capable of functioning at up to 40 Gbps in PAM3 mode, as well as offering a virtual GDDR7 memory controller. The device features bidirectional circuitry for executing read and write operations, and every pin is equipped with an extensive range of analog characterization features, such as skew injection with femto-second resolution, voltage control with millivolt resolution, programmable jitter injection, and various eye margining features critical for AC characterization and conformance testing. Furthermore, the system integrates device power supplies with precise power sequencing and ramping controls, providing a comprehensive solution for both AC characterization and memory functional stress testing on any GDDR7 device.

Introspects M5512 has been designed in close collaboration with JEDEC members working on the GDDR7 specification, so it promises to meet all of their requirements for compliance testing. Notably, however, the device does not eliminate need for interoperability tests and still requires companies to develop their own test algorithms, but it's still a significant tool for bootstrapping device development and getting it to the point where chips can begin interop testing.
“In its quest to support the industry on GDDR7 deployment, Introspect Technology has worked tirelessly in the last few years with JEDEC members to develop the M5512 GDDR7 Memory Test System,” said Dr. Mohamed Hafed, CEO at Introspect Technology.
GPUs



TSMC's 1.6nm Technology Announced for Late 2026: A16 with "Super Power Rail" Backside Power With the arrival of spring comes showers, flowers, and in the technology industry, TSMC's annual technology symposium series. With customers spread all around the world, the Taiwanese pure play foundry has adopted an interesting strategy for updating its customers on its fab plans, holding a series of symposiums from Silicon Valley to Shanghai. Kicking off the series every year – and giving us our first real look at TSMC's updated foundry plans for the coming years – is the Santa Clara stop, where yesterday the company has detailed several new technologies, ranging from more advanced lithography processes to massive, wafer-scale chip packing options.
Today we're publishing several stories based on TSMC's different offerings, starting with TSMC's marquee announcement: their A16 process node. Meanwhile, for the rest of our symposium stories, please be sure to check out the related reading below, and check back for additional stories.
- TSMC 2nm Update: N2 In 2025, N2P Loses Backside Power, and NanoFlex Brings Optimal Cells
- TSMC Preps Cheaper 4nm N4C Process For 2025, Aiming For 8.5% Cost Reduction
- TSMC's System-on-Wafer Platform Goes 3D: CoW-SoW Stacks Up the Chips
- TSMC Jumps Into Silicon Photonics, Lays Out Roadmap For 12.8 Tbps COUPE On-Package Interconnect
Headlining its Silicon Valley stop, TSMC announced its first 'angstrom-class' process technology: A16. Following a production schedule shift that has seen backside power delivery network technology (BSPDN) removed from TSMC's N2P node, the new 1.6nm-class production node will now be the first process to introduce BSPDN to TSMC's chipmaking repertoire. With the addition of backside power capabilities and other improvements, TSMC expects A16 to offer significantly improved performance and energy efficiency compared to TSMC's N2P fabrication process. It will be available to TSMC's clients starting H2 2026.
TSMC A16: Combining GAAFET With Backside Power Delivery
At a high level, TSMC's A16 process technology will rely on gate-all-around (GAAFET) nanosheet transistors and will feature a backside power rail, which will both improve power delivery and moderately increase transistor density. Compared to TSMC's N2P fabrication process, A16 is expected to offer a performance improvement of 8% to 10% at the same voltage and complexity, or a 15% to 20% reduction in power consumption at the same frequency and transistor count. TSMC is not listing detailed density parameters this far out, but the company says that chip density will increase by 1.07x to 1.10x – keeping in mind that transistor density heavily depends on the type and libraries of transistors used.
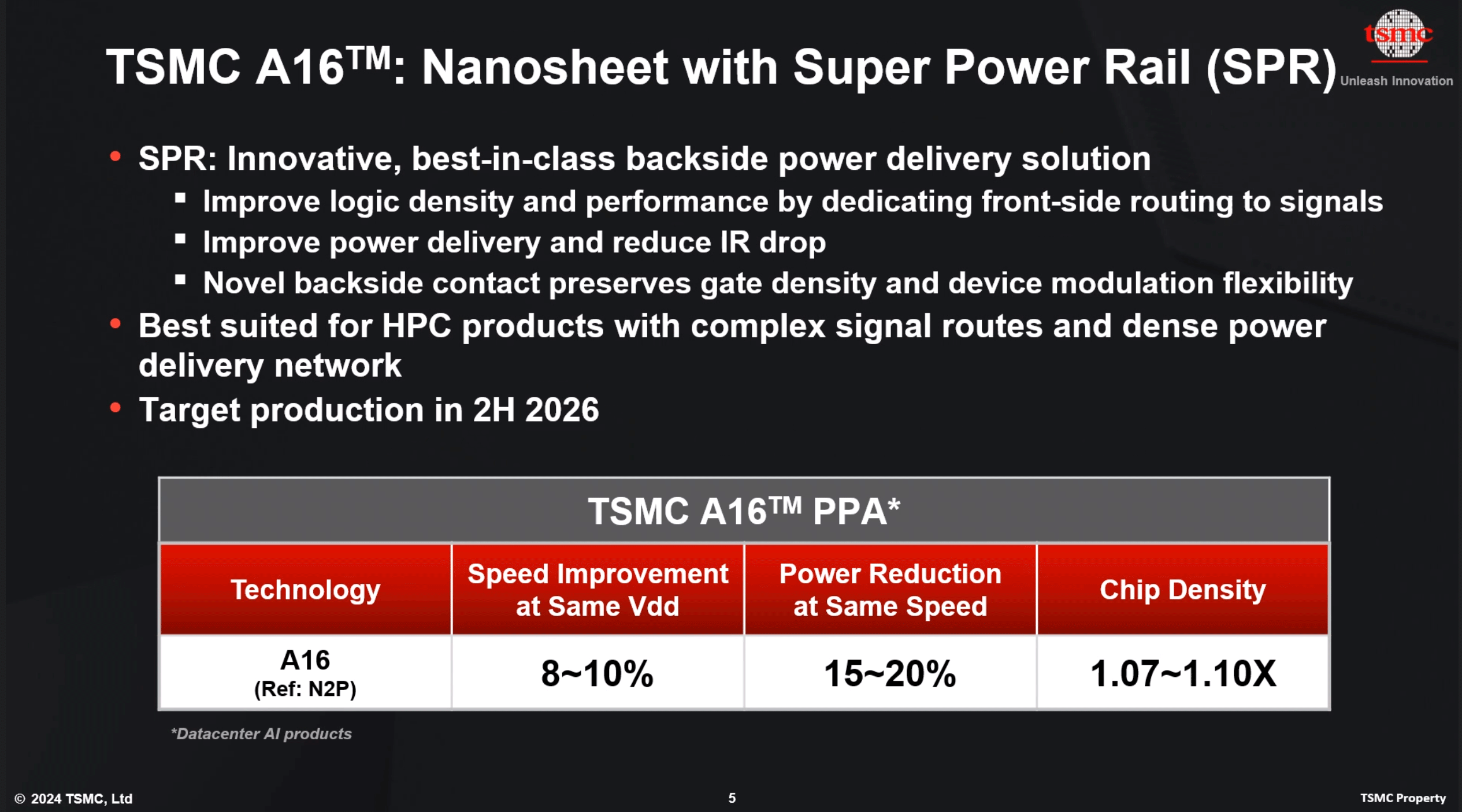
The key innovation of TSMC's A16 node, is its Super Power Rail (SPR) backside power delivery network, a first for TSMC. The contract chipmaker claims that A16's SPR is specifically tailored for high-performance computing products that feature both complex signal routes and dense power circuitry.
As noted earlier, with this week's announcement, A16 has now become the launch vehicle for backside power delivery at TSMC. The company was initially slated to offer BSPDN technology with N2P in 2026, but for reasons that aren't entirely clear, the tech has been punted from N2P and moved to A16. TSMC's official timing for N2P in 2023 was always a bit loose, so it's hard to say if this represents much of a practical delay for BSPDN at TSMC. But at the same time, it's important to underscore that A16 isn't just N2P renamed, but rather it will be a distinct technology from N2P.
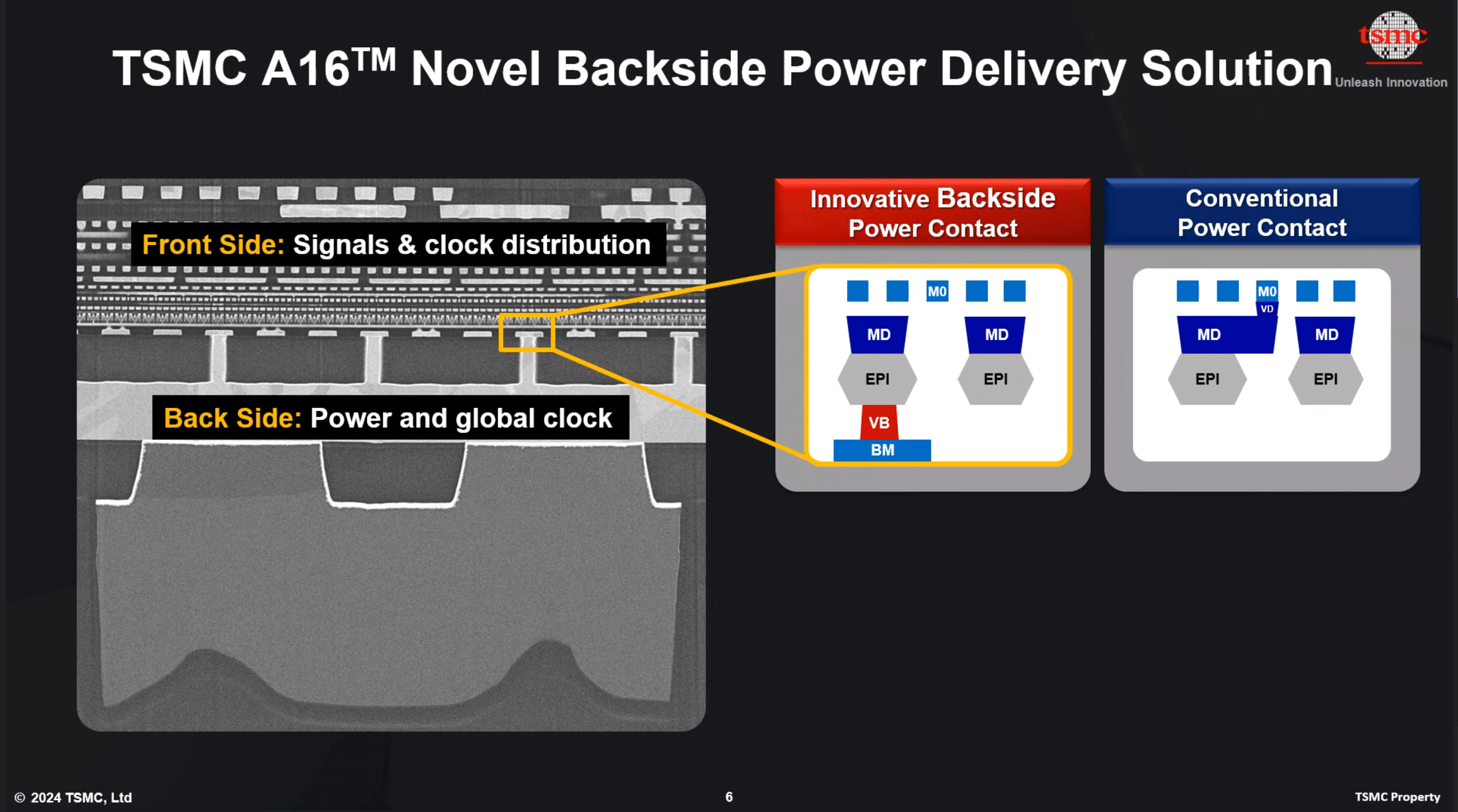
TSMC is not the only fab pursuing backside power delivery, and accordingly, we're seeing multiple variations on the technique crop up at different fabs. The... Semiconductors
Introspect Intros GDDR7 Test System For Fast GDDR7 GPU Design Bring Up
Introspect this week introduced its M5512 GDDR7 memory test system, which is designed for testing GDDR7 memory controllers, physical interface, and GDDR7 SGRAM chips. The tool will enable memory and processor manufacturers to verify that their products perform as specified by the standard.
One of the crucial phases of a processor design bring up is testing its standard interfaces, such as PCIe, DisplayPort, or GDDR is to ensure that they behave as specified both logically and electrically and achieve designated performance. Introspect's M5512 GDDR7 memory test system is designed to do just that: test new GDDR7 memory devices, troubleshoot protocol issues, assess signal integrity, and conduct comprehensive memory read/write stress tests.
The product will be quite useful for designers of GPUs/SoCs, graphics cards, PCs, network equipment and memory chips, which will speed up development of actual products that rely on GDDR7 memory. For now, GPU and SoC designers as well as memory makers use highly-custom setups consisting of many tools to characterize signal integrity as well as conduct detailed memory read/write functional stress testing, which are important things at this phase of development. But usage of a single tool greatly speeds up all the processes and gives a more comprehensive picture to specialists.
The M5512 GDDR7 Memory Test System is a desktop testing and measurement device that is equippped with 72 pins capable of functioning at up to 40 Gbps in PAM3 mode, as well as offering a virtual GDDR7 memory controller. The device features bidirectional circuitry for executing read and write operations, and every pin is equipped with an extensive range of analog characterization features, such as skew injection with femto-second resolution, voltage control with millivolt resolution, programmable jitter injection, and various eye margining features critical for AC characterization and conformance testing. Furthermore, the system integrates device power supplies with precise power sequencing and ramping controls, providing a comprehensive solution for both AC characterization and memory functional stress testing on any GDDR7 device.
Introspects M5512 has been designed in close collaboration with JEDEC members working on the GDDR7 specification, so it promises to meet all of their requirements for compliance testing. Notably, however, the device does not eliminate need for interoperability tests and still requires companies to develop their own test algorithms, but it's still a significant tool for bootstrapping device development and getting it to the point where chips can begin interop testing.
“In its quest to support the industry on GDDR7 deployment, Introspect Technology has worked tirelessly in the last few years with JEDEC members to develop the M5512 GDDR7 Memory Test System,” said Dr. Mohamed Hafed, CEO at Introspect Technology.
GPUs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's.
Intel Sells Its Arm Shares, Reduces Stakes in Other Companies
Intel has divested its entire stake in Arm Holdings during the second quarter, raising approximately $147 million. Alongside this, Intel sold its stake in cybersecurity firm ZeroFox and reduced its holdings in Astera Labs, all as part of a broader effort to manage costs and recover cash amid significant financial challenges.
The sale of Intel's 1.18 million shares in Arm Holdings, as reported in a recent SEC filing, comes at a time when the company is struggling with substantial financial losses. Despite the $147 million generated from the sale, Intel reported a $120 million net loss on its equity investments for the quarter, which is a part of a larger $1.6 billion loss that Intel faced during this period.
In addition to selling its stake in Arm, Intel also exited its investment in ZeroFox and reduced its involvement with Astera Labs, a company known for developing connectivity platforms for enterprise hardware. These moves are in line with Intel's strategy to reduce costs and stabilize its financial position as it faces ongoing market challenges.
Despite the divestment, Intel's past investment in Arm was likely driven by strategic considerations. Arm Holdings is a significant force in the semiconductor industry, with its designs powering most mobile devices, and, for obvious reasons, Intel would like to address these. Intel and Arm are also collaborating on datacenter platforms tailored for Intel's 18A process technology. Additionally, Arm might view Intel as a potential licensee for its technologies and a valuable partner for other companies that license Arm's designs.
Intel's investment in Astera Labs was also a strategic one as the company probably wanted to secure steady supply of smart retimers, smart cable modems, and CXL memory controller, which are used in volumes in datacenters and Intel is certainly interested in selling as many datacenter CPUs as possible.
Intel's financial struggles were highlighted earlier this month when the company released a disappointing earnings report, which led to a 33% drop in its stock value, erasing billions of dollars of capitalization. To counter these difficulties, Intel announced plans to cut 15,000 jobs and implement other expense reductions. The company has also suspended its dividend, signaling the depth of its efforts to conserve cash and focus on recovery. When it comes to divestment of Arm stock, the need for immediate financial stabilization has presumably taken precedence, leading to the decision.
CPUs
Kioxia Details BiCS 8 NAND at FMS 2024: 218 Layers With Superior Scaling
Kioxia's booth at FMS 2024 was a busy one with multiple technology demonstrations keeping visitors occupied. A walk-through of the BiCS 8 manufacturing process was the first to grab my attention. Kioxia and Western Digital announced the sampling of BiCS 8 in March 2023. We had touched briefly upon its CMOS Bonded Array (CBA) scheme in our coverage of Kioxial's 2Tb QLC NAND device and coverage of Western Digital's 128 TB QLC enterprise SSD proof-of-concept demonstration. At Kioxia's booth, we got more insights.
Traditionally, fabrication of flash chips involved placement of the associate logic circuitry (CMOS process) around the periphery of the flash array. The process then moved on to putting the CMOS under the cell array, but the wafer development process was serialized with the CMOS logic getting fabricated first followed by the cell array on top. However, this has some challenges because the cell array requires a high-temperature processing step to ensure higher reliability that can be detrimental to the health of the CMOS logic. Thanks to recent advancements in wafer bonding techniques, the new CBA process allows the CMOS wafer and cell array wafer to be processed independently in parallel and then pieced together, as shown in the models above.
The BiCS 8 3D NAND incorporates 218 layers, compared to 112 layers in BiCS 5 and 162 layers in BiCS 6. The company decided to skip over BiCS 7 (or, rather, it was probably a short-lived generation meant as an internal test vehicle). The generation retains the four-plane charge trap structure of BiCS 6. In its TLC avatar, it is available as a 1 Tbit device. The QLC version is available in two capacities - 1 Tbit and 2 Tbit.
Kioxia also noted that while the number of layers (218) doesn't compare favorably with the latest layer counts from the competition, its lateral scaling / cell shrinkage has enabled it to be competitive in terms of bit density as well as operating speeds (3200 MT/s). For reference, the latest shipping NAND from Micron - the G9 - has 276 layers with a bit density in TLC mode of 21 Gbit/mm2, and operates at up to 3600 MT/s. However, its 232L NAND operates only up to 2400 MT/s and has a bit density of 14.6 Gbit/mm2.
It must be noted that the CBA hybrid bonding process has advantages over the current processes used by other vendors - including Micron's CMOS under array (CuA) and SK hynix's 4D PUC (periphery-under-chip) developed in the late 2010s. It is expected that other NAND vendors will also move eventually to some variant of the hybrid bonding scheme used by Kioxia.
Storage
G.Skill Intros Low Latency DDR5 Memory Modules: CL30 at 6400 MT/s
G.Skill on Tuesday introduced its ultra-low-latency DDR5-6400 memory modules that feature a CAS latency of 30 clocks, which appears to be the industry's most aggressive timings yet for DDR5-6400 sticks. The modules will be available for both AMD and Intel CPU-based systems.
With every new generation of DDR memory comes an increase in data transfer rates and an extension of relative latencies. While for the vast majority of applications, the increased bandwidth offsets the performance impact of higher timings, there are applications that favor low latencies. However, shrinking latencies is sometimes harder than increasing data transfer rates, which is why low-latency modules are rare.
Nonetheless, G.Skill has apparently managed to cherry-pick enough DDR5 memory chips and build appropriate printed circuit boards to produce DDR5-6400 modules with CL30 timings, which are substantially lower than the CL46 timings recommended by JEDEC for this speed bin. This means that while JEDEC-standard modules have an absolute latency of 14.375 ns, G.Skill's modules can boast a latency of just 9.375 ns – an approximately 35% decrease.
G.Skill's DDR5-6400 CL30 39-39-102 modules have a capacity of 16 GB and will be available in 32 GB dual-channel kits, though the company does not disclose voltages, which are likely considerably higher than those standardized by JEDEC.
The company plans to make its DDR5-6400 modules available both for AMD systems with EXPO profiles (Trident Z5 Neo RGB and Trident Z5 Royal Neo) and for Intel-powered PCs with XMP 3.0 profiles (Trident Z5 RGB and Trident Z5 Royal). For AMD AM5 systems that have a practical limitation of 6000 MT/s – 6400 MT/s for DDR5 memory (as this is roughly as fast as AMD's Infinity Fabric can operate at with a 1:1 ratio), the new modules will be particularly beneficial for AMD's Ryzen 7000 and Ryzen 9000-series processors.
G.Skill notes that since its modules are non-standard, they will not work with all systems but will operate on high-end motherboards with properly cooled CPUs.
The new ultra-low-latency memory kits will be available worldwide from G.Skill's partners starting in late August 2024. The company did not disclose the pricing of these modules, but since we are talking about premium products that boast unique specifications, they are likely to be priced accordingly.
Memory
0 Comments